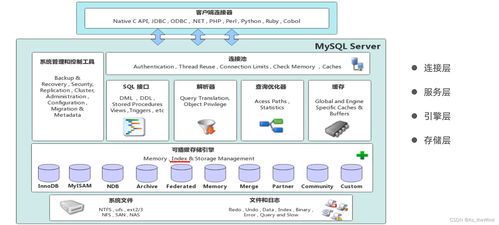
在當今數(shù)據(jù)驅(qū)動的時代,MySQL作為一款廣泛應用的關系型數(shù)據(jù)庫管理系統(tǒng),其進階知識對于構(gòu)建高效、穩(wěn)定和可靠的數(shù)據(jù)處理與存儲服務至關重要。本文將深入探討MySQL的三大核心進階主題:存儲引擎、索引優(yōu)化與事務處理,并結(jié)合CSDN等技術(shù)社區(qū)的最佳實踐,闡述它們?nèi)绾螢楝F(xiàn)代應用提供強大的數(shù)據(jù)處理與存儲支持。
一、 存儲引擎:數(shù)據(jù)存儲的基石
存儲引擎是MySQL的底層組件,負責數(shù)據(jù)的存儲、索引和事務管理。選擇合適的存儲引擎是優(yōu)化性能和數(shù)據(jù)完整性的第一步。
- InnoDB:默認且主流的引擎。它提供了完整的ACID事務支持、行級鎖和外鍵約束,非常適合處理高并發(fā)、需要事務保證的數(shù)據(jù)操作(如電商、金融系統(tǒng))。其支持MVCC(多版本并發(fā)控制),提升了讀寫并發(fā)性能。
- MyISAM:在MySQL 5.5之前是默認引擎。它不支持事務和外鍵,提供表級鎖。但其讀取速度快,支持全文索引,適用于“讀多寫少”、不需要事務的場景(如早期的內(nèi)容管理系統(tǒng)、數(shù)據(jù)倉庫查詢)。
- Memory:將所有數(shù)據(jù)存儲在RAM中,速度極快,但服務器重啟后數(shù)據(jù)會丟失。適用于臨時表、緩存或會話存儲。
- 其他引擎:如Archive(適用于日志類高壓縮存儲)、CSV(以CSV格式存儲)等,用于特定場景。
選擇建議:絕大多數(shù)生產(chǎn)環(huán)境應首選InnoDB。除非有非常明確的只讀、無事務需求,否則InnoDB在數(shù)據(jù)安全、并發(fā)和恢復方面的優(yōu)勢是無可替代的。
二、 索引優(yōu)化:查詢性能的加速器
索引是快速查找數(shù)據(jù)的數(shù)據(jù)結(jié)構(gòu)。沒有索引,MySQL只能進行全表掃描,效率極低。
- 索引類型:
- B-Tree索引:最常見的索引,適用于全值匹配、范圍查詢和前綴匹配。InnoDB和MyISAM都支持。
- 哈希索引:Memory引擎默認支持,精確匹配極快,但不支持范圍查詢和排序。InnoDB也支持自適應的哈希索引。
- 全文索引:用于文本內(nèi)容的全文搜索,MyISAM和InnoDB(5.6+)都支持。
- 空間索引:用于地理空間數(shù)據(jù)類型。
- 索引優(yōu)化策略:
- 前綴索引:對長字符串列,可以只索引前N個字符,節(jié)省空間。
- 覆蓋索引:查詢的所有列都包含在索引中,無需回表,極大提升性能。
- 最左前綴原則:聯(lián)合索引中,查詢條件必須從最左列開始,且不能跳過中間列,才能有效利用索引。
- 避免在索引列上使用函數(shù)或計算:如
WHERE YEAR(create<em>time) = 2023會導致索引失效,應改為范圍查詢WHERE create</em>time BETWEEN '2023-01-01' AND '2023-12-31'。
- 使用EXPLAIN分析:在SQL前加上
EXPLAIN關鍵字,可以查看MySQL的執(zhí)行計劃,是索引優(yōu)化的必備工具。
- CSDN等社區(qū)經(jīng)驗:技術(shù)博客中常分享的“索引失效”場景包括:like以通配符開頭(
'%abc')、OR條件兩側(cè)列未全部索引、數(shù)據(jù)類型隱式轉(zhuǎn)換等。定期查閱社區(qū)案例能有效避坑。
三、 事務處理:數(shù)據(jù)一致性的守護者
事務是保證一系列數(shù)據(jù)庫操作要么全部成功,要么全部失敗的機制,是數(shù)據(jù)一致性的核心。
- ACID特性:
- 原子性(Atomicity):事務內(nèi)的操作是一個不可分割的整體。
- 一致性(Consistency):事務使數(shù)據(jù)庫從一個一致狀態(tài)轉(zhuǎn)變到另一個一致狀態(tài)。
- 隔離性(Isolation):并發(fā)事務之間相互隔離,互不干擾。
- 持久性(Durability):事務提交后,對數(shù)據(jù)的修改是永久性的。
- 事務隔離級別(由低到高):
- 讀未提交(Read Uncommitted):可能讀到其他事務未提交的數(shù)據(jù)(臟讀)。
- 讀已提交(Read Committed):只能讀到已提交的數(shù)據(jù)。解決臟讀,但可能有不可重復讀問題。
- 可重復讀(Repeatable Read):MySQL InnoDB的默認級別。保證在同一事務中多次讀取同一數(shù)據(jù)結(jié)果一致。解決不可重復讀,但可能有幻讀問題(InnoDB通過MVCC和間隙鎖很大程度上解決了幻讀)。
- 串行化(Serializable):最高隔離級別,完全串行執(zhí)行,解決所有并發(fā)問題,但性能最低。
- 事務使用要點:
- 盡量讓事務簡短,避免長事務占用鎖資源。
- 根據(jù)業(yè)務場景選擇合適的隔離級別,默認的“可重復讀”在大多數(shù)情況下是平衡性能與一致性的最佳選擇。
- 善用
BEGIN/START TRANSACTION、COMMIT、ROLLBACK控制事務邊界。
四、 綜合應用:構(gòu)建穩(wěn)健的數(shù)據(jù)處理與存儲支持服務
將存儲引擎、索引優(yōu)化和事務處理結(jié)合起來,是構(gòu)建企業(yè)級數(shù)據(jù)處理和存儲支持服務的關鍵。
- 架構(gòu)設計:核心業(yè)務表(如訂單、用戶賬戶)必須使用InnoDB引擎,并設計合理的索引(如基于用戶ID、訂單時間的聯(lián)合索引)。日志、歸檔數(shù)據(jù)可考慮Archive或分區(qū)表。
- 開發(fā)規(guī)范:在代碼中明確事務邊界,對于資金、庫存等關鍵操作,務必使用事務保證一致性。編寫SQL時,時刻考慮索引是否有效。
- 運維與監(jiān)控:利用
SHOW ENGINE INNODB STATUS、慢查詢?nèi)罩镜裙ぞ弑O(jiān)控數(shù)據(jù)庫狀態(tài)。定期分析慢查詢,優(yōu)化索引和SQL語句。關注CSDN、官方文檔等渠道,跟進MySQL新版本特性(如InnoDB性能提升、在線DDL改進等)。 - 高可用與擴展:基于事務和復制技術(shù)(如主從復制、組復制),構(gòu)建讀寫分離、故障自動切換的高可用架構(gòu),確保數(shù)據(jù)處理服務的持續(xù)可用性。
****
深入理解MySQL的存儲引擎、索引優(yōu)化和事務處理,不僅是數(shù)據(jù)庫管理員(DBA)的職責,也是每一位后端開發(fā)者的必備技能。通過合理運用這些進階知識,并積極借鑒CSDN等技術(shù)社區(qū)分享的實戰(zhàn)經(jīng)驗,我們能夠設計并維護出高性能、高可靠的數(shù)據(jù)處理與存儲系統(tǒng),為上層應用提供堅實的數(shù)據(jù)服務支撐。持續(xù)學習與實踐,是應對日益復雜的數(shù)據(jù)挑戰(zhàn)的不二法門。